
그래프와 트리는 정점(Node)과 간선(Edge)으로 이루어진 자료구조입니다. 점과 선을 통해 데이터를 저장하기 때문에, 그래프의 경우 도로, 전력망, 네트워크 등 우리가 살고있는 실제 세계를 모델링하는데 많이 사용되며 트리의 경우 컴퓨터의 디렉토리와 같은 계층 구조를 모델링하는데 사용됩니다.
어떤 트리나 그래프에서 특정 노드를 찾기 위해서는 구조 전체를 탐색할 필요가 있습니다. 기존 자료구조의 형식이나 특징에 따라 효율적인 탐색을 할 수 있도록 하는 몇 가지 방법이 있는데, 대표적으로 BFS(Breadth-First Search)와 DFS(Depth-First Search) 두 가지가 있습니다.
오늘 포스팅에서는 이 두 가지 탐색 방법들의 특징과 각 방법을 사용하기 좋은 케이스 등을 알아보겠습니다.
BFS (Breadth-First Search)
BFS는 시작 노드에서 출발해 인접한 노드들을 먼저 방문하고, 그 뒤에 방문한 노드의 인접한 노드들을 방문하는 과정을 반복하는 방법으로, 너비 우선 탐색이라고도 부릅니다.
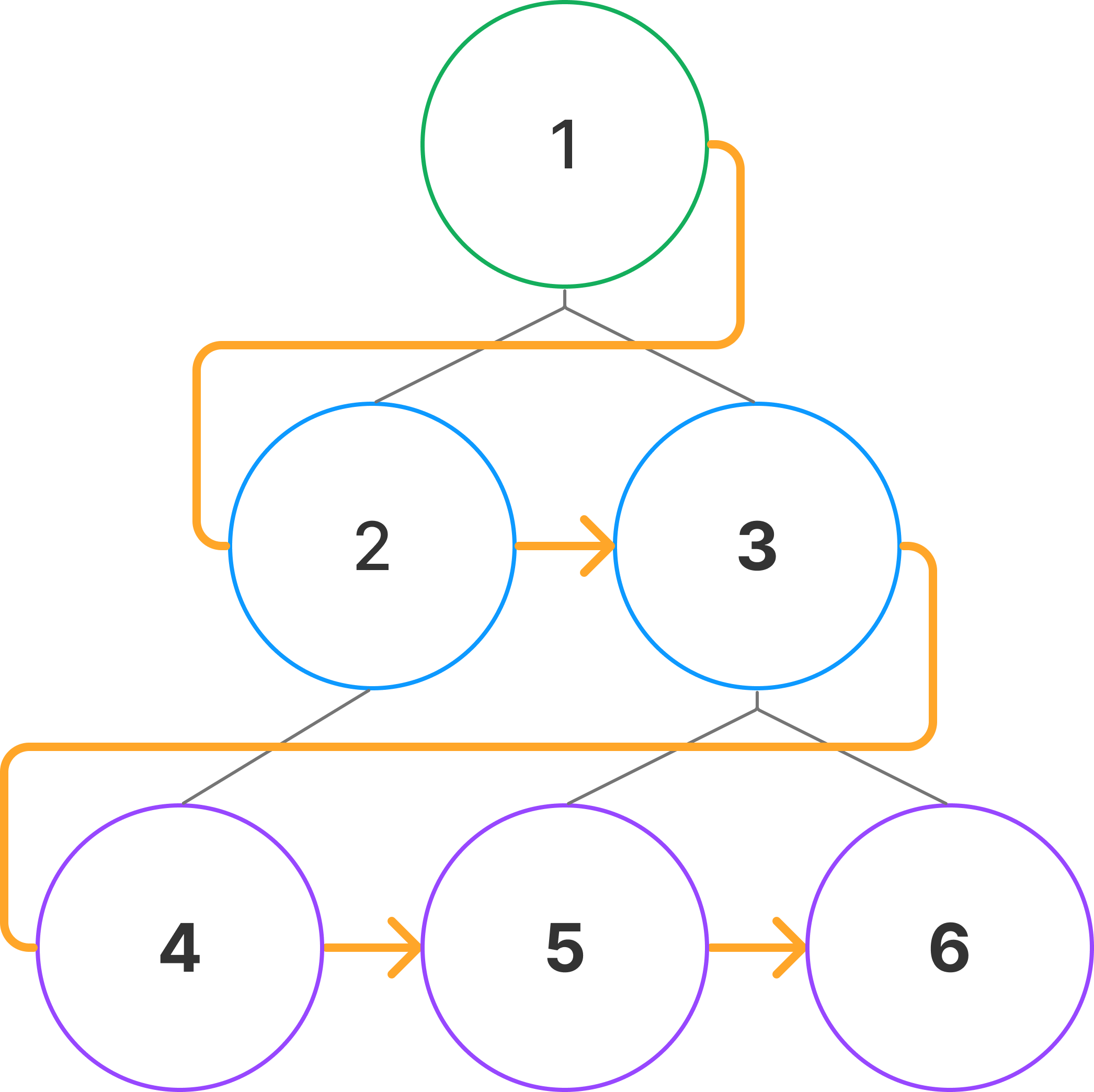
트리를 순회하는 모양이 너비(breadth) 방향으로 퍼지는 것과 같다고 하여 너비 우선 탐색이라는 이름이 붙었는데, 이후에 나올 DFS의 모양과 비교하면 적절한 이름이라고 느껴집니다.
BFS의 경우 인접 노드를 우선적으로 탐색하기 때문에, 루트 노드로부터의 거리가 가장 가까운 최단 경로를 찾는데에 많이 사용됩니다. 특히 각 간선에 가중치가 있는 경우에도 유용하게 사용할 수 있습니다.
그럼 자바스크립트를 이용하여 BFS를 구현해보겠습니다.
// graph = {1: [2, 3], 2: [4], 3: [5, 6]}
function bfs(graph, start) {
const visited = new Set([start]);
const queue = [start];
const dist = new Map([[start, 0]]);
while (queue.length > 0) {
const current = queue.shift();
for (const target of graph[current]) {
if (!visited.has(target)) {
visited.add(target);
queue.push(target);
dist.set(target, dist.get(current) + 1);
}
}
}
return dist;
}
먼저 방문 여부를 확인하는 visited, 방문지에 대한 정보를 갖고있는 queue, 시작점으로부터의 거리를 가진 dist, 이렇게 세 가지 변수를 만들고 시작합니다. 변수 이름에서 알 수 있듯, BFS는 FIFO(First-In-First-Out) 의 특성을 이용하기 때문에 queue를 사용합니다.
순회는 단일 방향으로만 진행되어야 효율적인 시간 내로 탐색을 마칠 수 있기 때문에, 방문 여부를 확인하는 배열은 꼭 필요합니다.
함수의 초기 세팅 이후, 탐색을 반복하는 과정을 보면 다음과 같습니다.
- queue.shift() 로 queue에 있던 맨 앞의 요소를 꺼내오고, 배열에서 제거합니다. pop()을 맨 앞에서 한 것과 같습니다.
- 인접한 노드들을 하나씩 확인합니다. 만약 방문했던 노드가 아니라면 방문한 노드 목록(visited)에 추가합니다.
- 해당 노드를 방문 할 노드 목록(queue)에 추가합니다.
- 해당 노드까지의 거리에 현재 노드까지의 거리 + 1 (또는 가중치) 을 추가하여 저장합니다.
이런식으로, BFS를 이용하면 시작 지점부터 점차 거리가 멀어지는 순으로 노드들을 순회할 수 있게 됩니다.
DFS (Depth-First Search)
BFS는 시작 노드에서 출발해 발견된 노드들을 계속해서 탐색하고, 탐색이 끝나면 이전으로 돌아가 다른 노드들을 방문하는 과정을 반복하는 방법으로, 깊이 우선 탐색이라고도 부릅니다.
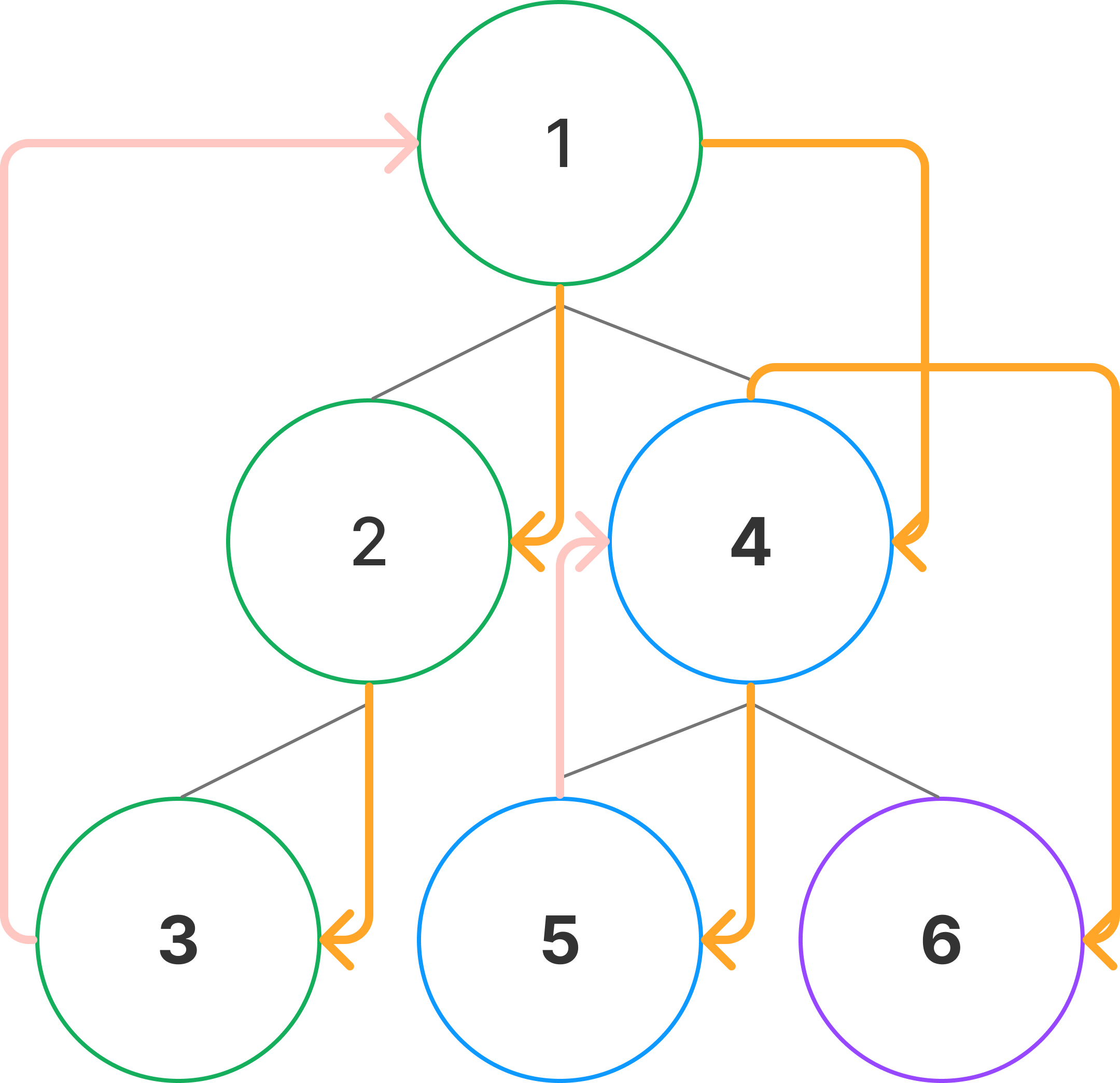
진행 과정 예시 그림을 보면 한 번 찾은 경로를 끝까지 탐색하는 모습을 보입니다. 트리 구조로 보았을때 너비 방향이 아닌 깊이가 깊어지는 방향으로 탐색을 진행하는 특징을 보입니다.
DFS의 경우 BFS와는 다르게 깊이 하나의 경로를 완벽하게 탐색하기 때문에 그래프에서 사이클을 찾거나 미로 경로 탐색 등에 사용하면 효율적인 동작을 기대할 수 있습니다.
다음은 자바스크립트로 구현한 DFS입니다.
// graph = {1: [2, 3], 2: [4], 3: [5, 6]}
function dfs(graph, start) {
const visited = new Set();
function dfsRecursion(node) {
visited.add(node);
graph[node].forEach((neighbor) => {
if (!visited.has(neighbor)) {
dfsRecursion(neighbor);
}
});
}
dfsRecursion(start);
}
BFS와 마찬가지로 방문 여부를 확인하는 visited 변수를 만들고, 순회를 위한 dfsRecursion 함수를 정의하는 것으로 시작합니다. DFS는 FILO(First-In-Last-Out) 의 특성을 이용하기 때문에 Stack를 사용하여 구현할 수 있습니다. 여기서는 Stack을 구현하는 대신, 재귀 호출을 통해 함수 호출 스택을 쌓는 방법을 이용하여 DFS를 구현하였습니다.
재귀가 일어나는 과정을 살펴보겠습니다.
- start 노드를 입력받아 재귀 함수에 진입합니다.
- 입력으로 들어온 노드를 방문한 노드에 추가합니다.
- 그래프 상에 노드와 인접한 노드들을 forEach 반복문을 통해 검사합니다.
- 인접한 노드가 방문했던 노드인지 확인하고, 그렇지 않다면 재귀 호출을 통해 위 과정을 다시 반복합니다.
이런식으로 진행되면, 다음 forEach 반복이 진행되기 전에 인접한 노드들이 먼저 함수 호출 스택에 올라가 해당 경로의 탐색이 끝나기 전까지는 다른 인접 노드를 탐색하는 과정이 잠시 보류됩니다.
DFS를 구현할때 한 가지 생각해 볼 부분이 있습니다. 위의 코드에서는 인접 리스트를 사용하여 DFS를 구현하였는데, 인접 행렬을 사용해서도 DFS를 구현할 수 있습니다. 다만 이런 경우엔 모든 노드에 대해 탐색을 수행해야 하기 때문에 불필요한 탐색이 일어날 가능성이 높습니다.
특히 탐색해야 하는 대상이 트리 구조처럼 희소 행렬로 나타나는 경우나 엄청나게 큰 그래프를 탐색하는 작업을 해야한다면 이러한 차이는 특히 두드러지기 때문에 예시처럼 인접 리스트를 활용하는 것이 좋습니다.
마치며
오늘은 간단하면서도 대표적인 탐색 방법인 BFS와 DFS에 대해 알아보았습니다. 다음에는 그래프에서 사용할 수 있는 또 다른 탐색 방법들에 대해 알아보겠습니다. 틀린 코드나 설명은 댓글로 알려주시면 감사하겠습니다.
읽어주셔서 감사합니다.
'이론 > 알고리즘' 카테고리의 다른 글
| 최단 경로 찾기 : 플로이드 워셜(Floyd-Warshall) 알고리즘 (0) | 2023.05.21 |
|---|---|
| 최단 경로 찾기 : 다익스트라(Dijkstra) 알고리즘 (0) | 2023.04.02 |
| [C++] 백준 13549번: 숨바꼭질 3 (0) | 2021.10.07 |
| [C++] BOJ 에서 정해지지 않은만큼의 입력을 받을 때 (0) | 2021.08.24 |
| 백준 1463번: 1로 만들기 (0) | 2018.08.06 |




댓글